
I have a pandas dataframe. Suppose we have the following pandas dataframe that contains data about 8 basketball players on 2 different teams: Def samplestrat(df, stratifying_column_name, num_to_sample, maxrows_to_est = 10000, bw_per_range = 50, eval_points = 1000 ): Web a stratified sample is one that takes a sample with an even amount of representation from a certain group within the population. I am trying to create a sample dataframe with replacement and also stratify it.
Return a random sample of items from an axis of object. Web you can use sklearn's train_test_split function including the parameter stratify which can be used to determine the columns to be stratified. We’ll implement stratified sampling using pandas methods groupby () and apply (): Suppose you’re carrying out a survey of households in a city.
Return a random sample of items from an axis of object. Def samplestrat(df, stratifying_column_name, num_to_sample, maxrows_to_est = 10000, bw_per_range = 50, eval_points = 1000 ): Cannot be used with frac.
How To Perform Stratified Sampling In Pandas (With Examples)

Before we dive into the code, it’s important to understand the concept of stratified sampling. You will need these imports: Web answers to this question recommend using the pandas sample method or the train_test_split function.
Systematic Sampling in Pandas

This method is used to ensure that the sample accurately represents the. If the number of samples is the same for every group, or if the proportion is constant for every group, you could try.
PYTHON Stratified Sampling in Pandas YouTube

We use lambda function to execute sample () on each group. This is the function i am currently using: Web stratified sampling is a sampling technique used to obtain samples that best represent the population..
Stratified Random Sampling Using Python and Pandas

Web stratified sampling in pandas is a data sampling technique that involves dividing a dataset into subgroups or strata based on specific characteristics or attributes. Web a simple explanation of how to perform stratified sampling.
What Is Stratified Sampling and How to Do It Using Pandas? Proclus

Suppose we have the following pandas dataframe that contains data about 8 basketball players on 2 different teams: Separating the population into homogeneous groupings called strata and randomly sampling data from each stratum decreases bias.
Pandas random sampling stratified and weighted
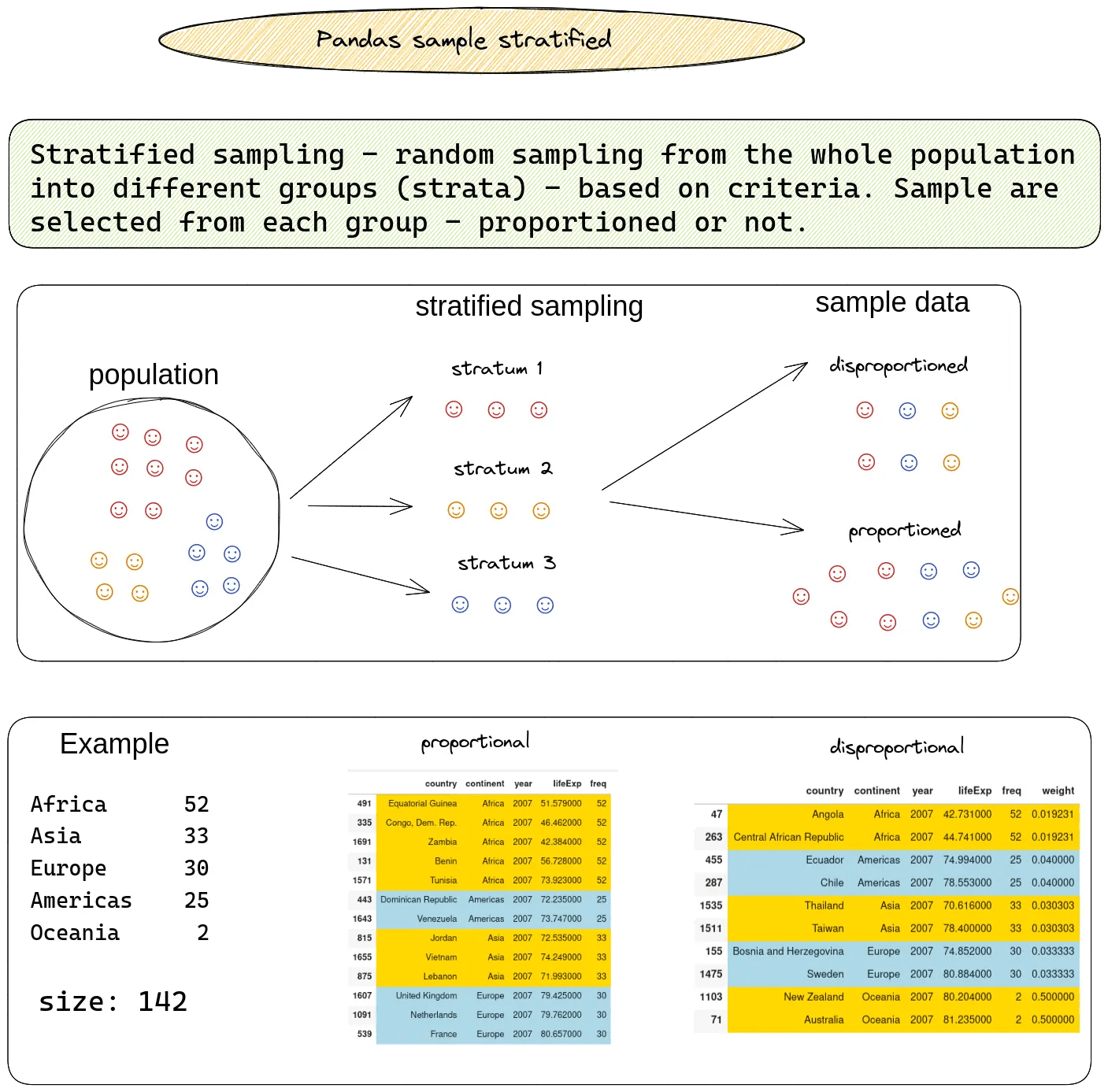
It involves dividing the population into subgroups or strata based on certain characteristics and then selecting samples from each stratum proportionally. Modified 4 years, 7 months ago. Web a stratified sample is one that takes.
What Is Stratified Sampling and How to Do It Using Pandas? Proclus

Web stratified random sampling using python and pandas. This is the function i am currently using: Web this tutorial explains two methods for performing stratified random sampling in python. Suppose we have the following pandas.
This allows me to replace: If the number of samples is the same for every group, or if the proportion is constant for every group, you could try something like. Web the stratified sampling technique means that your sample data will have the same target distribution as your population data. Web this tutorial explains two methods for performing stratified random sampling in python. ['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b'], 'position':
Return a random sample of items from an axis of object. But none of these solutions seem to generalize well to n splits and none provides a stratified split. This method is used to ensure that the sample accurately represents the.
Web Stratified Sampling Is A Sampling Technique Used To Obtain Samples That Best Represent The Population.
Web you can use sklearn's train_test_split function including the parameter stratify which can be used to determine the columns to be stratified. Then use apply() to sample 20% rows within each group. For example if we were taking a sample from data relating to individuals we might want to make sure we had equal representation of men and women or equal representation from each age group. '''take a sample of dataframe df stratified by.
How To Stratify Sample Data To Match Population Data In Order To Improve The Performance Of Machine Learning Algorithms.
Web dataframe.sample(n=none, frac=none, replace=false, weights=none, random_state=none, axis=none, ignore_index=false) [source] #. Number of items from axis to return. Before we dive into the code, it’s important to understand the concept of stratified sampling. The concept of stratified sampling.
Return A Random Sample Of Items From An Axis Of Object.
Suppose we have the following pandas dataframe that contains data about 8 basketball players on 2 different teams: This is the function i am currently using: This method is used to ensure that the sample accurately represents the. In this instance, your primary dataset will be seen as your population, and the samples drawn from it will be used for training and testing.
I Am Trying To Create A Sample Dataframe With Replacement And Also Stratify It.
Given that the variables are binned, the following one liner should give you the desired output. This allows me to replace: It involves dividing the population into subgroups or strata based on certain characteristics and then selecting samples from each stratum proportionally. Assert 0.0 < sampling_rate <= 1.0 assert groupby_column in df.columns num_rows = int((df.shape[0] * sampling_rate) // 1) num_classes = len(df[groupby_column].unique()).
If the number of samples is the same for every group, or if the proportion is constant for every group, you could try something like. We use lambda function to execute sample () on each group. Suppose we have the following pandas dataframe that contains data about 8 basketball players on 2. Each class represents a distinct category or label. ['a', 'a', 'a', 'a', 'b', 'b', 'b', 'b'], 'position':